Mastering Microservices a Practical Exploration — Conquering Complexity
A Step-By-Step Guide: Build Microservices Like a Pro
Concept
- Microservices is an architectural style for building software applications as a collection of small, independent services.
- Each service focuses on a specific business capability and is self-contained. They may communicate with others via middlewares or APIs.
When should we use Microservices?
It depends… In short, the decision to use microservices should be proportional to the complexity of the system being developed.

The decision of choice should be based on complexity analysis vs the benefits.
- The complexity of the system being developed ? : Consider the project’s size, requirements, number of teams involved, and performance/scalability needs, as these factors influence whether microservices are necessary.
- Level of complexity you’re willing to handle ? : Assess your team’s capacity and expertise in managing complexities such as automated deployments, monitoring, and infrastructures associated with microservices architecture.
- Analyze — Do benefits outweigh all these complexities ? : Carefully weigh the benefits of microservices, including improved modularity, scalability, and advancement of business functions, against the additional complexities they introduce. Only adopt microservices if the benefits significantly outweigh the challenges involved.
Either Monolithic or Microservice — Keep in mind, that once the project is built, the journey starts from there.
Sometimes going directly into the microservices architecture may be risky too. At such times, a monolithic may help in exploring the complexity of the system and understanding its boundaries. However, this may only be beneficial if you need to access the boundaries of the system first — to analyze if there’s a necessity to introduce the complexity of additional distribution.
Building with Microservices - A Simple Exploration
Let’s learn and understand the simple microservice-architecture based application. This is not a perfect model but will serve our purpose.
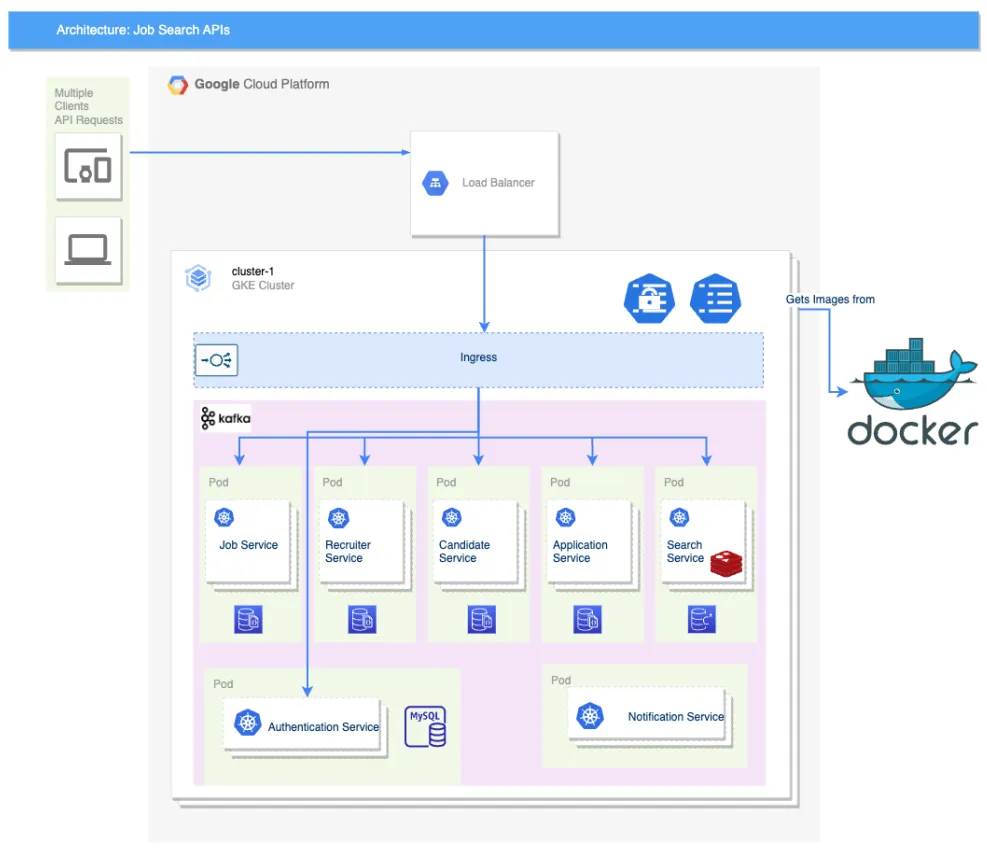
Let’s analyze this demo Job Portal System — we want to learn microservices by mimicking the business model of the Job Search Application. We’ll keep things simple, avoiding detailed discussions on technology, projects, or languages. We are already set with the microservice architecture for this system. Now, Our focus is on grasping the architecture’s complexity vs benefits, analyzing decisions, and learning from any missteps encountered. Let’s understand the different components and their boundaries first.
Understand Component Boundaries
- Job Service: Stores and manages all job information. (create/update/delete jobs)
- Recruiter Service: Profile for all — recruiters, agencies, and clients (pay-to-use modal, registration, and compliance).
- Candidate Service: Profile for candidates. (Candidate details, documents, images and parsed details)
- Application Service: Accepts resumes from candidates. (form-based inputs, PDF parsing, ATS processors)
- Search Service: Provides information about all job details and candidate details. (search-optimized, data cache, and performance).
- Authentication Service: Handles user login and signup.
- Notification Service: Sends notifications to candidates — async-operations. (send email)
Breakdown - Complexity vs. Benefits
- Benefits: Independent services offer cool perks — Imagine each service scaling on its own, handling crashes without affecting others, and updating independently. Scalability, fault isolation, and independent deployment.
- Complexity: There’s a catch — Communicating between services can be tricky, keeping everything consistent takes effort, and development might feel more complex. Communication overhead, distributed consistency, and increased development effort.
Support Layers — Storage & Communication
- Storage: Database — Service-specific data store. MySQL, MongoDB, Cassandra, ElasticSearch. Cache — Redis Cache, HazleCast, Apache Ignite. Object Storage — MinIO, S3. Graph — Neo4j or Amazon Neptune. etc.
- Middlewares: Messaging system for asynchronous real-time communication between services. Apache Kafka, RabbitMQ, Amazon SQS
Resilience, Decoupling and Flexibility
Let’s take an simple example between Components - Job Service and Search Service: Job Service stores everything job-related, and the Search Service relies on that data to recommend the perfect fit. How do they talk to each other?
- Resilience: Direct communication is straightforward but not ideal. What if one service fails? It could disrupt the entire system. A decoupling and asynchronous communication may be a better option.
What about other cases where a direct communication is required ? REST or RPC calls — Yes, the choice depends on need… But the services should still be fault-tolerant, and implement fallback mechanisms and circuit breakers. Else its just a microservice architecture resembling monolithic, where a single failure propagates across the entire system. For direct communication also consider service discovery and load balancing.
- Decoupling: A solution is to use middleware like Kafka or RabbitMQ. They work as a central message hub, facilitating asynchronous communication between services. How it works — The Job Service publishes updates (e.g. a new job is created/updated or deleted). to the middleware. Then, the search service would subscribe to this message and store it in an optimized way.
Do decoupled services solves everything? No… Decoupling services often adds more need for data communication and also spreads out the data. So, Clear protocols and more back-and-forth communication may be required to ensure smooth integration and data integrity.
- Flexibility: Each service relies on its own DataStore or Shared DataStore but should be able to independently add/utilize any support layers as needed. The search service would use elastic search as datastore and integrate with Redis Cache to enhance the retrieval speed. This can be achieved with any service — offering a flexible and scalable solution.
Flexibility is always beneficial ? Usually.. It’s tempting, but it also adds complexity. Choosing the right tools must be the balance between the need and manageability.
Support layers offer incredible benefits, but don’t blindly split services or add more support layers. Ensure each service offers clear benefits and justifies its complexity.
Configuration, Deployment, and Observability
While breaking down your application into smaller, independent services offers scalability, flexibility, and resilience, it also introduces new manageability challenges:
Configuration:
Problem: Management Madness — Each service might have its own configuration needs, and manually navigating to each-and-every service just to update its config, secret & properties is tedious and error-prone. This could potentially lead to inconsistencies, complexity, and concerns for security.
Solution: One Source of Truth — Store common configurations in a single location, ensuring everyone plays by the same rules. i.e. A central config server or central config location. Tools like Vault, Kubernetes Secrets, or Cloud-config help in securely managing sensitive data, secrets, and encryption keys.
Deployment:
Managing numerous individual deployments can be cumbersome and error-prone compared to a monolithic application.
Automation — Automation tools to the rescue. Tools like Jenkins, Ansible, Terraform, Chef, and Puppet can automate infrastructures, builds, and deployment tasks. They eliminate manual steps, saving you time and preventing frustrating errors. Remember, start small! Experiment with basic automation before tackling complex workflows. Understand the needs of the project and the expertise of the team.
Automation Script + Orchestration tools — Finding different tools and the right combinations can be frustrating, as learning and configuring the right combo can be tricky. Utilize the pre-ready Containerization & Orchestration tools: Use Docker to create a portable standalone image independent of the environment. Use orchestration tools like Kubernetes to automate, orchestrate, scale, and manage these containers. This will be suitable despite of any deployment choices.
Server: Deployments Options — Self-managed infrastructure or Cloud Comfort: Build and automate your infrastructure for deployments, it provides full control, flexibility, and potential cost savings too. However, it will also bring complexities & responsibilities to manage, and maintain. Another option is to utilize Cloud Comfort: Leverage on-demand cloud services for hassle-free deployments. If you are using Kubernetes (k8s) popular cloud platforms like AWS, Google and Azure offer managed Kubernetes service, GKE, EKS, and AKS.
Check More On: Service Mesh — a control pane that provides ad-hoc functionalities outside microservice code. Chaos engineering — tools to inject controlled chaos and test your system’s resilience. Also see: Kubernetes-wheel by bytebytego: k8s-wheel.png
Diagram: Infrastructure & Practices - Managed vs Cloud or A Combo
Observability — Logging & Monitoring:
Ongoing automated deployments, multiple services, and their instances tracking and monitoring them becomes a daunting task. With robust monitoring tools and log-capturing strategies, this can shed light on your running microservice ecosystem.
Logging:
Log aggregation: Aggregate application logs to the centralized log storage. One popular option is to use ELK Stack (Elasticsearch, Logstash, Kibana) for centralized log storage and analysis.
Distributed Tracing — It’s vital to trace the intricate journeys of requests across the services, to understand the hidden bottlenecks and errors. An alternative specifically with the Spring Framework is to use Zipkin and a Cloud-Sleuth for centralized log and request tracing.
Monitoring:
Collect and visualize service metrics for performance insights. This visibility helps to identify potential issues and improve overall performance.
Built-in Metrics and Custom Analysis: Platforms like Kubernetes and cloud providers like AWS, Google Cloud, and Azure offer a predefined set of metrics. Custom Analysis: For deeper insights, tools like Prometheus can help in metrics collections. Frameworks like Spring provide both tools like Micrometer and Prometheus for easier metric extraction and collection.
Visualization: The collected metrics can be visualized in the dashboards with clearer pictures of health and performance. Cloud providers often offer pre-built dashboards. Third-party tools like Grafana provide flexible and customizable dashboards.
Conclusion
Microservices hold immense promise, but embarking on this journey requires careful consideration. Build the necessary foundation, adopt a learning mindset, and gradually explore advanced practices. Remember, with great power comes a great responsibility… and a great complexity, but it’s a rewarding journey.
Please feel free to checkout this project. https://github.com/ashrawan/swa-proj3. This demo application aims to assist in understanding and creating microservices using Spring Framework. It walks you through the thought processes, steps, and key decisions involved in building this project, providing valuable insights and serving as inspiration for this blog. The road to mastery is paved with continuous learning and experimentation. 😊